👋 Welcome to Track #1: Driving with Language of the 2025 RoboSense Challenge!
In the era of autonomous driving, it is increasingly critical for intelligent agents to understand and act upon language-based instructions. Human drivers naturally interpret complex commands involving spatial, semantic, and temporal cues (e.g., "turn left after the red truck" or "stop at the next gas station on your right").
To enable such capabilities in autonomous systems, vision-language models (VLMs) must be able to perceive dynamic driving scenes, understand natural language commands, and make informed driving decisions accordingly.
🏆 Prize Pool: $2,000 USD (1st: $1,000, 2nd: $600, 3rd: $400) + Innovation Awards
🎯 Objective
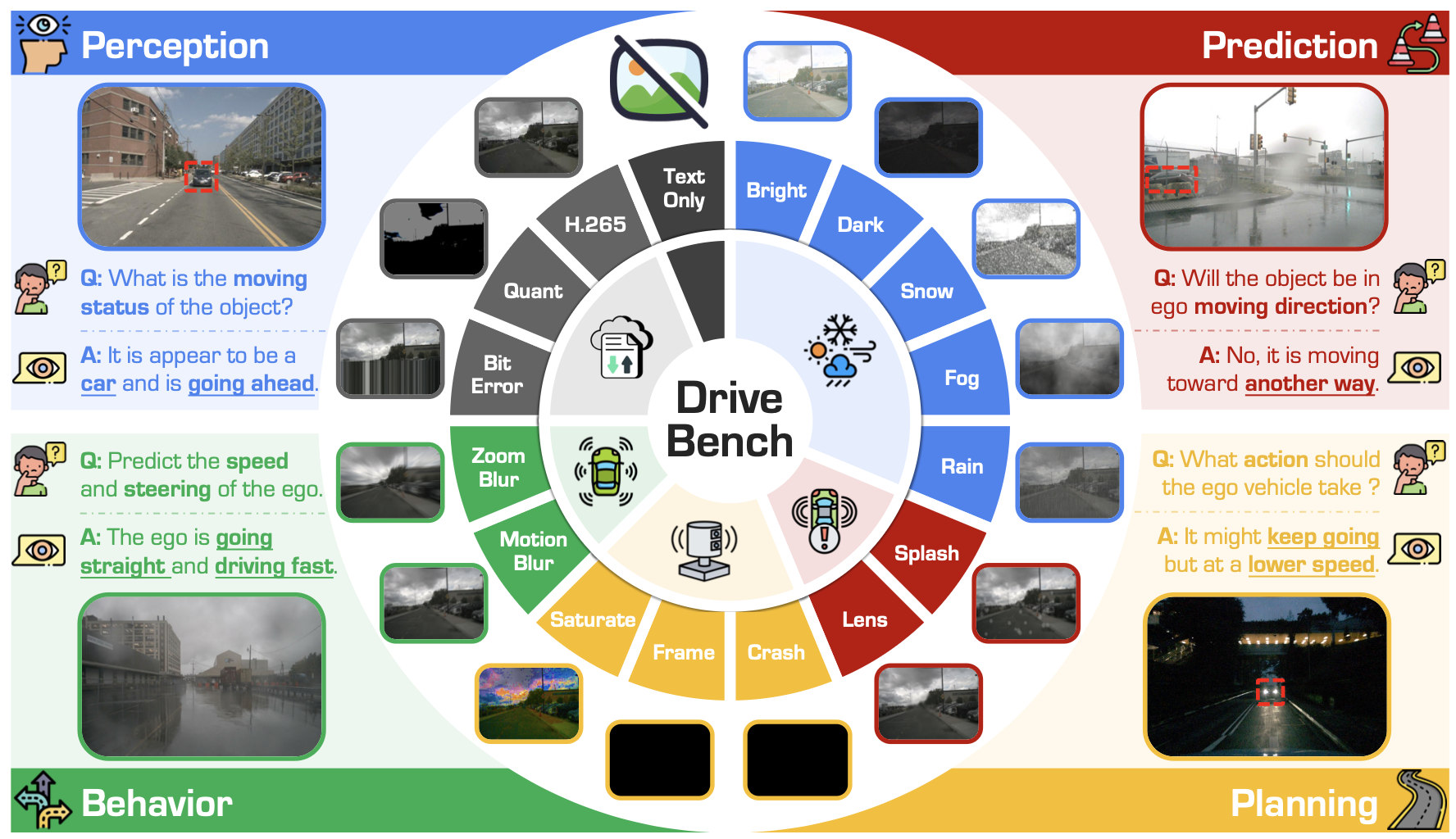
This track evaluates the capability of VLMs to answer high-level driving questions in complex urban environments. Given question including perception, prediction, and planning, and a multi-view camera input, participants are expected to answer the question given the visual corrupted images.
🗂️ Phases & Requirements
Phase #1: Clean Image Evaluation
Duration: June 15th, 2025 (anytime on earth) - August 15th, 2025 (anytime on earth)
In this phase, participants are expected to answer the high-level driving questions given the clean images.
Specifically, participants are expected to:
- Fine-tune the VLM on custom datasets (including nuScenes, DriveBench, etc.)
- Develop and test the approaches
- Submit results as a json file
- Iterate and improve their models based on public leaderboard feedback
Ranking Metric: The weighted score combining:
- Accuracy
- LLM-based score
Phase #2: Corruption Image Evaluation
Duration: August 15th, 2025 (anytime on earth) - September 15th, 2025 (anytime on earth)
In this phase, participants are expected to answer the high-level driving questions given the corrupted images.
Specifically, participants are expected to:
- Fine-tune the VLM on custom datasets (including nuScenes, DriveBench, etc.)
- Develop and test their approaches
- Submit results as a json file
- Iterate and improve their models based on public leaderboard feedback
Ranking Metric: The weighted score combining:
- Accuracy
- LLM-based score
🚗 Dataset Examples




📊 Metrics
The evaluation uses two primary metrics to assess the model performance:
Primary Metrics
| Metric | Usage | Description |
|---|---|---|
| Accuracy | Multi-Choice Questions (MCQs) | Exact match between predicted and ground truth answers |
| LLM Score | Visual Question Answering (VQA) | Score from 0-10 assigned by an LLM evaluator using detailed rubrics |
Final Score Calculation
The final ranking is determined by a weighted combination of both Phase 1 and Phase 2:
This weighting aims to emphasize the importance of robust performance under different visual corruptions (Phase 2), while maintaining baseline capabilities on clean images (Phase 1).
🛠️ Baseline Model
In this track, we adopt the popular Qwen2.5-VL7B as our baseline model. The code is available and free to use at our GitHub repository: https://github.com/robosense2025/track1.
The model weights can be downloaded from here: https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct.
Beyond the provided baseline, participants are free and encouraged to explore alternative strategies to further boost performance:
- Retrieval-augmented reasoning
- Multi-frame visual reasoning
- Chain-of-thought reasoning
- Graph-based reasoning
- Vision-based object reference prompting
📊 Baseline Results
The baseline performance of the Qwen2.5-VL7B model on Phase 1 is as follows:
| Task | Question Type | Accuracy (%) |
|---|---|---|
| Perception | MCQ | 75.5 |
| VQAobj | 29.2 | |
| VQAscene | 22.2 | |
| Prediction | MCQ | 59.2 |
| Planning | VQAobj | 29.6 |
| VQAscene | 31.2 | |
| Average | All Types | 42.5 |
The baseline performance of the Qwen2.5-VL7B model on Phase 2 is as follows:
To be updated.
🔗 Resources
We provide the following resources to support the development of models in this track:
| Resource | Link | Description |
|---|---|---|
| GitHub Repository | github.com/robosense2025/track1 | Baseline code and setup instructions |
| HuggingFace Dataset | huggingface.co/datasets/robosense/datasets | Dataset with training and test splits |
| Baseline Model | Qwen2.5-VL-7B-Instruct | Weights of the baseline model |
| Registration Form | Google Form (Closed on August 15th) | Team registration for the challenge |
| Evaluation Server | CodaBench Platform | Online evaluation platform |
❓ Frequently Asked Questions
Here, we provide a list of Frequently Asked Questions (FAQs) below for better clarity. If you have additional questions on the details about this competition, please reach out at robosense2025@gmail.com.
What VLMs can we use?
The participants are free to use any VLMs that are open-sourced, such as Qwen, Phi, LLaVA, or your own VLMs. However, the closed-source VLMs, including GPT-4o, Claude 3.5 Sonnet, Gemini 2.0 Pro, Grok 4, etc., are NOT allowed to use in this track.
What should I submit for reproducibility?
If using an existing open-source VLM, please submit your code. If you have performed any fine-tuning, you must also submit the trained weights. Additionally, we strongly recommend including:
• A README file explaining environment setup and usage
• An inference script to directly launch for reproduction
Submissions that CAN NOT be reproduced on our end will be considered INVALID.
Why are the evaluation results different using the same prediction file?
We use LLM to evaluate open-ended questions. The MCQs result should the the same, while open-ended questions might vary within a small numerical range.
Can we modify the prompt?
Yes, you are free to modify the prompts. This includes techniques such as prompt engineering, retrieval-augmented generation (RAG), and in-context learning. However, to ensure correct evaluation, please DO NOT alter the question field in your submission JSON file.
Can we use external models?
No. This competition is intended to evaluate the capabilities of VLMs specifically. The use of task-specific models (e.g., object detectors, trajectory predictors) that directly address the task or provide extra information to the VLMs is NOT allowed. Modification within the VLM architectures is allowed, such as the vision encoder.
📖 References
@misc{robosense2025track1,
title = {RoboSense Challenge 2025: Track 1 - Driving with Language},
author = {RoboSense Challenge 2025 Organizers},
year = {2025},
howpublished = {https://robosense2025.github.io/track1}
}