👋 Welcome to Track #2: Social Navigation of the 2025 RoboSense Challenge!
This track challenges participants to develop advanced RGBD-based perception and navigation systems that empower autonomous agents to interact safely, efficiently, and socially in dynamic human environments.
Participants are expected to design algorithms that interpret human behaviors and contextual cues to generate navigation strategies that strike a balance between navigation efficiency and social compliance. Submissions must address key challenges such as real-time adaptability, occlusion handling, and ethical decision-making in socially complex settings.
🏆 Prize Pool: $2,000 USD (1st: $1,000, 2nd: $600, 3rd: $400) + Innovation Awards
🎯 Objective
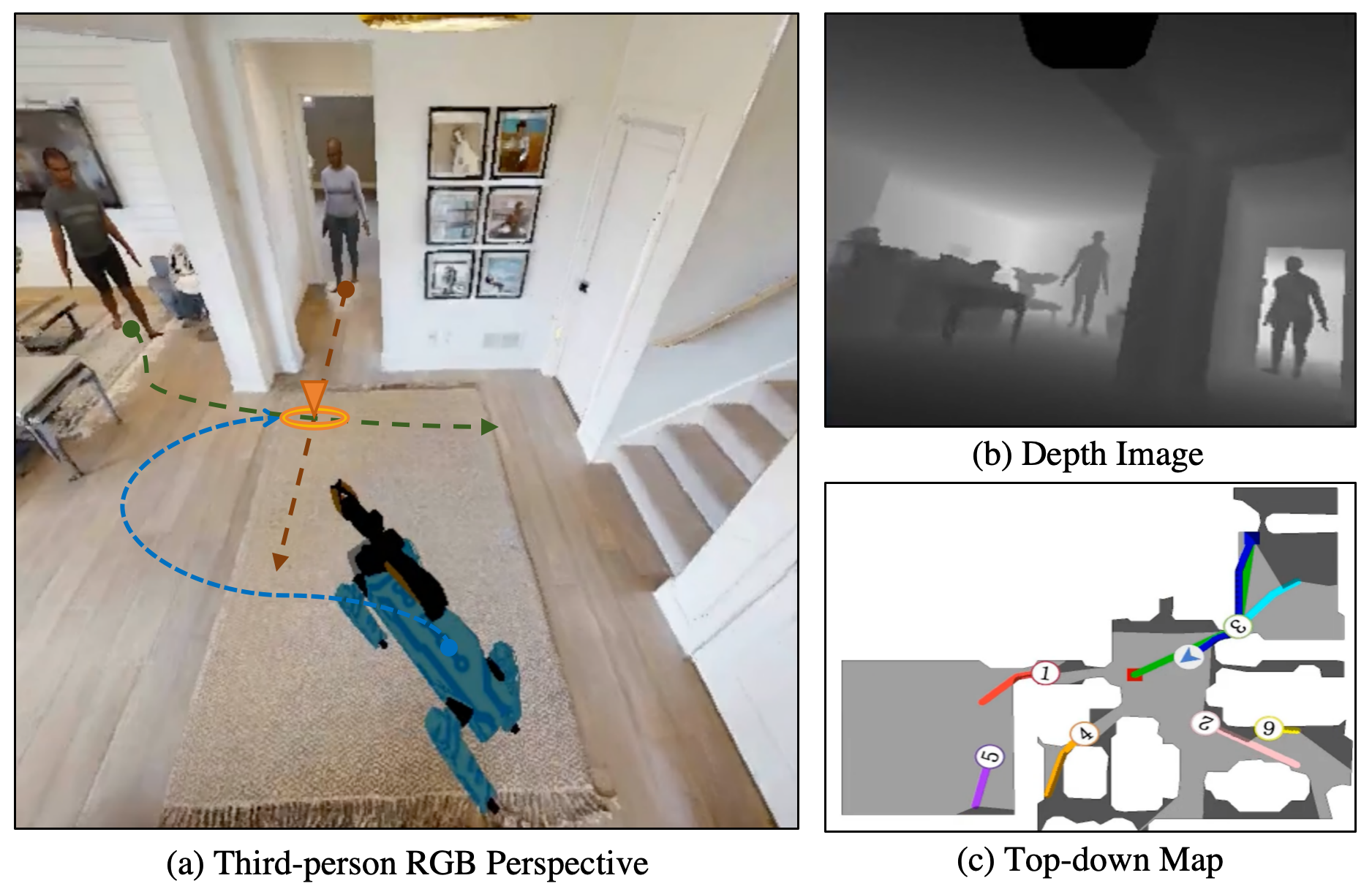
This track evaluates an agent's ability to perform socially compliant navigation in dynamic indoor environments populated with realistic human agents. Participants must design navigation policies based solely on RGBD observations and odometry, without access to global maps or privileged information.
- Social Norm Compliance: Agents must maintain safe distances, avoid collisions, and demonstrate socially acceptable behaviors.
- Realistic Benchmarking: Navigate in large-scale, photo-realistic indoor scenes with dynamic, collision-aware humans from the Social-HM3D and Social-MP3D datasets
- Egocentric Perception: Agents operate from a first-person perspective, relying solely on their onboard sensors. This includes color sensing, depth information, and relative goal coordinates, simulating how a robot would perceive its surroundings.
Ultimately, the aim is to develop socially-aware agents that can navigate safely, efficiently, and naturally in environments shared with humans.
🗂️ Phases & Requirements
All times mentioned are in the Anywhere on Earth (AoE) timezone (UTC-12).
Minival Phase: Sanity Check
🎯 Public train set validation (~10 episodes)
Duration: June 15th, 2025 (anytime on earth) - September 15th, 2025 (anytime on earth)
Participants are expected to:
Each team is allowed a maximum of 3 submissions per day in this phase. Please use them judiciously.
Phase #1: Public Evaluation
🎯 Public test set evaluation (~1000 episodes)
Duration: June 15th, 2025 (anytime on earth) - August 15th, 2025 (anytime on earth)
Participants are expected to:
Each team is allowed 1 submission per day, with a total limit of 10 submissions in this phase.
Phase #2: Final Evaluation
🎯 Private test set evaluation (~500 episodes)
Duration: August 15th, 2025 (anytime on earth) - September 15th, 2025 (anytime on earth)
Important Note:
Teams that were unable to submit evaluations during Phase #1 are welcome to continue participating in Phase #2. The final ranking will be determined solely by the results from Phase #2.
Participants are expected to:
Each team is allowed 2 submission per day, with a total limit of 20 submissions in this phase.
🗄️ Dataset
The track uses the RoboSense Track 2 Social Navigation Dataset, based on the Social-HM3D benchmark.
Our benchmark datasets are designed to reflect realistic, diverse, and socially complex navigation environments:
- Goal-driven Trajectories: Humans navigate with intent, avoiding random or repetitive paths.
- Natural Behaviors: Movement includes walking, pausing, and realistic avoidance via ORCA.
- Balanced Density: Human count is scaled to scene size, avoiding over- or under-crowding.
- Diverse Environments: Includes 844 scenes for Social-HM3D.
| Dataset | Num. of Scenes | Scene Types | Human Num. | Natural Motion |
|---|---|---|---|---|
| Social-HM3D | 844 | Residence, Office, Shop, etc. | 0-6 | ✔️ |
🎬 Dataset Examples
We showcase some classic encounter episodes in the benchmark. These require the robot to proactively avoid the human using socially-aware behaviors.
Frontal Approach
Blind Corner
📊 Evaluation Metrics
Our benchmark focuses on two key aspects: task completion and social compliance.
| Metric | Description |
|---|---|
| SR (Success Rate) | Fraction of episodes where the robot successfully reaches the goal. |
| SPL (Success weighted by Path Length) | Penalizes inefficient navigation. Rewards shorter, successful paths. |
| PSC (Personal Space Compliance) | Measures how well the robot avoids violating human personal space. A higher PSC indicates better social behavior. The threshold is set to 1.0m, considering a 0.3m human radius and 0.25m robot radius. |
| H-Coll (Human Collision Rate) | The proportion of episodes involving any human collision. Collisions imply task failure. |
| 🎯 Total Score | Weighted combination of the core metrics: Total = 0.4 x SR + 0.3 x SPL + 0.3 x PSC. This combined score reflects the overall navigation quality while implicitly penalizing human collisions. |
The evaluation metrics and scoring formula remain the same for both Phase #1 and Phase #2.
The final rankings will be determined by the results from Phase #2 only. Rankings are based on the Total Score, with ties broken by the higher Success Rate (SR).
🛠️ Baseline Model
The baseline model is built upon the Falcon framework, which integrates the following core components:
- Egocentric Policy: Uses only camera and point-goal inputs, with no access to maps or human positions.
- Auxiliary Supervision: Trains with privileged cues and removed during evaluation.
- Future Awareness: Learns from human future trajectories to avoid long-term collisions.
- Robust Environment: Trained in realistic scenes with dynamic crowds for strong generalization.
Falcon serves as a strong and socially intelligent baseline for this challenge, effectively combining auxiliary learning and future-aware prediction to navigate in complex human environments.
📊 Baseline Results
The Falcon baseline achieves the following performance on Phase #1 using Social-HM3D (~1,000 test episodes):
| Dataset | Success ↑ | SPL ↑ | PSC ↑ | H-Coll ↓ |
|---|---|---|---|---|
| Social-HM3D | 55.15 | 55.15 | 89.56 | 42.96 |
Note: These results represent the baseline performance on the 24GB GPU version used for Phase #1 evaluation. Participants are encouraged to develop novel approaches to surpass the results.
🔗 Resources
We provide the following resources to support the development of models in this track:
| Resource | Link | Description |
|---|---|---|
| GitHub Repository | https://github.com/robosense2025/track2 | Baseline code and setup instructions |
| Dataset | HuggingFace Dataset | Dataset with training and test splits |
| Baseline Model | Pre-Trained Model | Weights of the baseline model |
| Registration | Google Form (Closed on August 15th) | Team registration for the challenge |
| Evaluation Server | EvalAI Platform | Online evaluation platform |
❓ Frequently Asked Questions
Here, we provide a list of Frequently Asked Questions (FAQs) below for better clarity. If you have additional questions on the details about this competition, please reach out at robosense2025@gmail.com.
Why are my results not showing on the leaderboard?
The most common reason is that your submission did not generate a valid result.json file in the expected format. Please ensure your submission:
- Produces a valid JSON file at
output/result.json - Contains all required metrics:
SR,SPL,PSC,H-Coll - Uses the correct numerical format (floating-point values)
Example of correct format:
"SR": 0.50,
"SPL": 0.45,
"PSC": 0.60,
"H-Coll": 0.02
}
How do I handle different dependencies or environment requirements?
If your submission requires additional dependencies:
- Minor dependencies: Add installation commands to your
run.shscript using conda/pip - Major differences: Contact us via email (robosense2025@gmail.com), Slack, or WeChat for assistance
Example run.sh with dependency installation:
# Install additional dependencies
conda install -c conda-forge your_package
pip install specific_library==1.2.3
# Run your inference
source activate falcon
python your_inference_script.py
What is the correct dataset path for my code?
To simplify evaluation, we use a fixed dataset mount point inside the evaluation Docker container:
Important: Your code should always read data from this path, regardless of which phase is being evaluated. Our backend automatically mounts the appropriate dataset for each phase to this location.
What are the differences between Phase 1 and Phase 2?
All submissions are evaluated inside Docker images with the following versions:
- Phase 1:
docker pull zeyinggong/robosense_socialnav:v0.5 - Phase 2:
docker pull zeyinggong/robosense_socialnav:v0.7
Key Changes in v0.7:
- Fixed driver compatibility issues due to EGL errors
- Multi-environment support: Phase 2 supports up to 8 environments for evaluation
- Updated action space: The action set has been refined to clearly distinguish between stopping (ending an episode) and pausing (remaining stationary). A new move_backward action is also introduced.
1 - move_forward
2 - turn_left
3 - turn_right
4 - move_backward # newly added action for moving backward
5 - pause # newly added action for pausing without movement
The two new actions (4-move_backward, 5-pause) are optional. Teams can continue using only actions 0-3 from Phase 1. Therefore, the action space is fully backward-compatible with Phase 1, ensuring smooth transition for existing methods.
How can I test my submission locally?
For Phase 2, we recommend using Docker image v0.7 for local testing:
--gpus all \
--runtime=nvidia \
-v /path/to/your/submission:/app/Falcon/input:ro \
-v /path/to/your/data:/app/Falcon/data:ro \
zeyinggong/robosense_socialnav:v0.7
You can manually execute your run.sh inside the container to verify correctness.
Tip: Refer to the provided Baseline ZIP Submission Example (Updated) for reference.
Note: Phase 2 does not support action submissions since the test dataset is not publicly available.
How long does evaluation take?
- Minival Phase: 5-10 minutes
- Phase 1 Full Evaluation: 3-5 hours (depending on queue length and inference runtime)
- Phase 2 Full Evaluation: 2-4 hours (depending on number of environments used, queue length, and inference runtime)
If your submission remains pending for over 48 hours, please:
- Open an issue on our GitHub repository
- Contact us at robosense2025@gmail.com
Can I modify the evaluation pipeline or import custom code?
Yes, we encourage flexible approaches! You have significant freedom to modify the evaluation pipeline and import your own policy code, including:
Falcon/habitat-baselines/habitat_baselines/eval.py(main evaluation script)Falcon/habitat-baselines/habitat_baselines/rl/ppo/falcon_evaluator.py(evaluator implementation)
You can import and integrate your custom modules, modify the inference pipeline, or adapt the evaluation logic to suit your approach.
⚠️ However, the following restrictions must be respected:
- Open-source models only: You cannot use proprietary pretrained models or private datasets that are not publicly accessible
- No bypassing simulation: You cannot circumvent the simulator's navigation logic to directly generate result files
- No bypassing evaluation constraints: You cannot circumvent the restrictions enforced in
falcon_evaluator.py, including accessing extra environmental information or sensors beyond the allowed observation keys, or any other validation checks
These restrictions ensure fair competition while maintaining the scientific integrity of the challenge.
🆘 Still need help?
If your question isn't answered here, please reach out to us:
- Email: robosense2025@gmail.com
- GitHub Issues: Track 2 Issues
- Competition Website: RoboSense 2025
📖 References
@article{gong2024cognition,
title = {From Cognition to Precognition: A Future-Aware Framework for Social Navigation},
author = {Gong, Zeying and Hu, Tianshuai and Qiu, Ronghe and Liang, Junwei},
journal = {arXiv preprint arXiv:2409.13244},
year = {2024}
}
@misc{robosense2025track2,
title = {RoboSense Challenge 2025: Track 2 - Social Navigation},
author = {RoboSense Challenge 2025 Organizers},
year = {2025},
howpublished = {https://robosense2025.github.io/track2}
}